
Ny Apple-stödd AI-modell kan generera ljud och tal från tysta videor
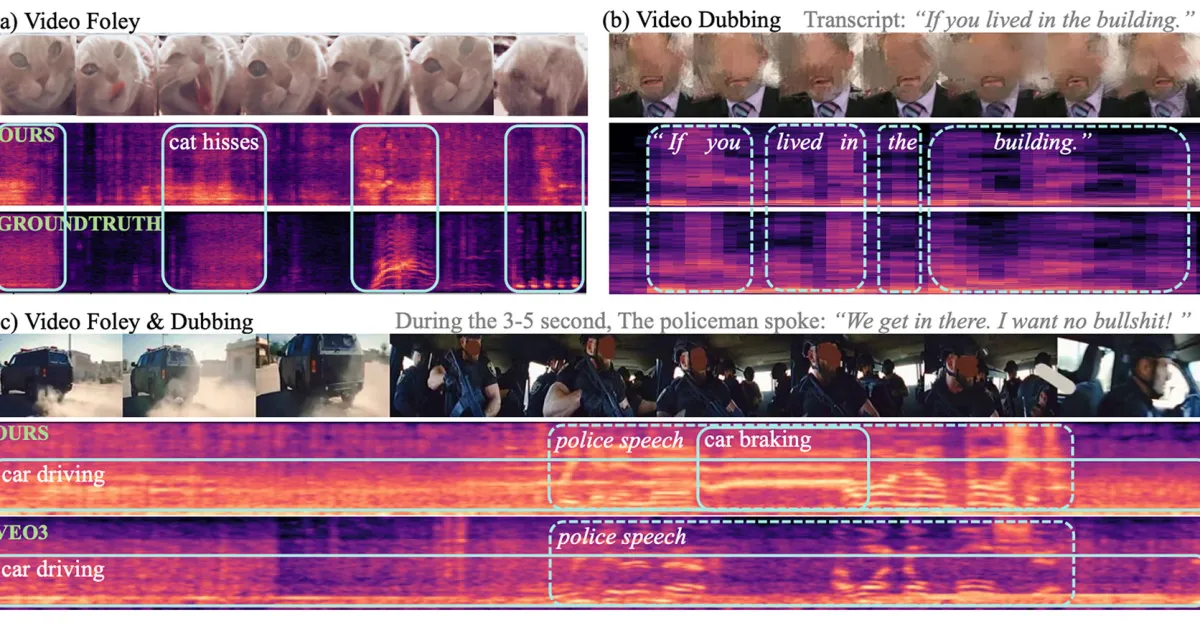
Apple har utvecklat en AI-modell, VSSFlow, som kan generera ljud och tal från tysta videor med hög kvalitet.
Apple har utvecklat en AI-modell, VSSFlow, som kan generera ljud och tal från tysta videor med hög kvalitet.

Apple har utvecklat AI-modellen SlowFast-LLaVA-1.5 för effektiv analys av långa videor, som presterar bättre än större modeller. Den kombinerar detaljerad och snabb analys av bildrutor och är tillgänglig som open source.

Apples forskare har utvecklat en anpassad språkmodell som överträffar större modeller i analys och förståelse av långformatvideo.

Forskare från Apple och Tel-Aviv universitet har utvecklat en metod för att effektivisera AI-baserad text-till-tal-generering genom att gruppera liknande ljud, utan att påverka förståeligheten.

Apple har utvecklat en AI-modell som förbättrar lågljusbilder på iPhone genom att integrera en diffusionsbaserad bildmodell i kamerans bildbehandling, vilket återfår detaljer från råsensorinformation.
© 2008 – 2026 Aapl.se - Byggt med Rails och en kärlek för RSS. Allt innehåll tillhör respektive ägare